1 Regression Output Table Examples
#I AM MAKING A CHANGE-YILDIZ ALTIN!
This RMD file was one of the examples you worked through in 380. I’m including it in this example for a few reasons. First, you can see how RMD files that you used before as standalone RMD files to create standalone HTML output can be combined in a book using bookdown. Second, this file loads data using read.csv("data/ceo.csv"), serving as an example of how you will store all data in a “data” folder put in the main project folder. Third, this file provides examples of showing regression output side by side.
Note: Generally it’s a good idea to load your packages in a code chunk at the top rather than mixed in with the rest of the document. However, for this example I am going to load the packages in the same code chunk where I use them so that you can see exactly what package is needed for specific functions.
The dataset ceo.csv has the following variables:
| Variable | Description |
|---|---|
salary |
1990 compensation in dollars ($) |
age |
age of CEO in years |
comten |
years CEO with company |
ceoten |
years as ceo with company |
sales |
1990 firm sales in $millions |
profits |
1990 profits in $millions |
mktval |
1990 market value in $millions |
1.1 Summary Statistics
The stargazer package provides an easy way to display summary statistics. You need the result='asis' codechunk option so that it displays the html table in the knit output file. The warning=FALSE and message=FALSE keeps it from displaying some of the messages it displays by default. One limitation of the table output is that it doesn’t leave much space horizontally. This can be controlled by HTML options for cell padding in tables.
library(stargazer)
mydata <- read.csv("data/ceo.csv")
stargazer(mydata, type = "html",summary.stat = c("n","mean","sd", "min", "median", "max"))| Statistic | N | Mean | St. Dev. | Min | Median | Max |
| salary | 177 | 865,864.400 | 587,589.300 | 100,000 | 707,000 | 5,299,000 |
| age | 177 | 56.429 | 8.422 | 33 | 57 | 86 |
| comten | 177 | 22.503 | 12.295 | 2 | 23 | 58 |
| ceoten | 177 | 7.955 | 7.151 | 0 | 6 | 37 |
| sales | 177 | 3,529.463 | 6,088.654 | 29 | 1,400 | 51,300 |
| profits | 177 | 207.831 | 404.454 | -463 | 63 | 2,700 |
| mktval | 177 | 3,600.316 | 6,442.276 | 387 | 1,200 | 45,400 |
1.2 Model comparisons
Consider four models:
model1 <- lm(salary~sales+mktval+profits,data=mydata)
model2 <- lm(salary~sales+mktval+profits+age,data=mydata)
model3 <- lm(salary~sales+mktval+profits+ceoten,data=mydata)
model4 <- lm(salary~sales+mktval+profits+ceoten+age,data=mydata)One package that allows you to report the results for all four models is the stargazer package. This produces a table similar to the esttab output in Stata. Remember that each column is a separate model and if a variable does not have a coefficient displayed in a column, that means it was not included as an explanatory variable in that model.
| Dependent variable: | ||||
| salary | ||||
| (1) | (2) | (3) | (4) | |
| sales | 15.984 | 15.369 | 18.233* | 18.061 |
| p = 0.152 | p = 0.169 | p = 0.100 | p = 0.106 | |
| mktval | 23.831 | 23.842 | 21.157 | 21.231 |
| p = 0.137 | p = 0.137 | p = 0.183 | p = 0.183 | |
| profits | 31.703 | 28.100 | 48.636 | 47.528 |
| p = 0.909 | p = 0.920 | p = 0.859 | p = 0.863 | |
| age | 4,528.026 | 823.966 | ||
| p = 0.353 | p = 0.873 | |||
| ceoten | 12,730.860** | 12,390.430** | ||
| p = 0.026 | p = 0.042 | |||
| Constant | 717,062.400*** | 464,424.700* | 613,958.800*** | 570,743.300** |
| p = 0.000 | p = 0.093 | p = 0.000 | p = 0.042 | |
| Observations | 177 | 177 | 177 | 177 |
| R2 | 0.178 | 0.182 | 0.201 | 0.202 |
| Adjusted R2 | 0.163 | 0.163 | 0.183 | 0.178 |
| Residual Std. Error | 537,420.300 (df = 173) | 537,621.100 (df = 172) | 531,159.300 (df = 172) | 532,670.100 (df = 171) |
| F Statistic | 12.464*** (df = 3; 173) | 9.559*** (df = 4; 172) | 10.846*** (df = 4; 172) | 8.633*** (df = 5; 171) |
| Note: | p<0.1; p<0.05; p<0.01 | |||
1.2.1 Adjusted R-Squared
Recall the definition of \(R^2\): \[ R^2 = \frac{SSE}{SST} = 1 - \frac{SSR}{SST} \]
The denominator measures the total variation in the \(y\) variable: \(SST = (n-1)Var(y)\). Thus, it has nothing to do with the explanatory variables. Adding additional \(x\) variables does not affect \(SST\). Adding an additional \(x\) variable cannot decrease how much of the variation in \(y\) explained by the model, so \(SSE\) will not decrease. Usually it increases at least a little bit. Thus, adding an additional \(x\) variable cannot decrease \(R^2\), and it usually increases it at least a little bit. This means that \(R^2\) increasing is a not a good justification for adding an additional \(x\) variable to the model.
Adjusted \(R^2\), often denoted \(\bar{R}^2\), penalizes you for adding an additional \(x\) variable. Adjusted \(R^2\) only increases if the new variable has a sufficiently significant effect on \(y\). Adjusted \(R^2\) is defined as
\[ \bar{R}^2 = 1 - \frac{\left(\frac{SSR}{n-k-1}\right)}{\left(\frac{SST}{n-1}\right)} \]
Look at the models above. All four models include measures of the company, including sales, market value, and profits. Models 2-4 add variables measuring characteristics of the CEO. Compare models 1 and 2. Adding the CEOs age increases \(R^2\) but adjusted \(R^2\) does not increase, indicating that adding age does not improve the model. Comparing models 1 and 3, both \(R^2\) and adjusted \(R^2\) increase when adding the CEO’s tenure, indicating this variable does improve the model. Comparing models 3 and 4, we again see that adding the CEO’s age does not improve the model; \(R^2\) increases slightly but adjusted \(R^2\) goes down.
1.3 Test Linear Combinations of Parameters
Consider again Model 3. I’ll display the estimates again here to demonstrate using the kable() from knitr and broom)
library(knitr)
library(broom)
model3 <- lm(salary~sales+mktval+profits+ceoten,data=mydata)
kable(tidy(model3),digits = 2)| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | 613958.78 | 65486.13 | 9.38 | 0.00 |
| sales | 18.23 | 11.01 | 1.66 | 0.10 |
| mktval | 21.16 | 15.79 | 1.34 | 0.18 |
| profits | 48.64 | 273.37 | 0.18 | 0.86 |
| ceoten | 12730.86 | 5635.96 | 2.26 | 0.03 |
It looks like the coefficient on profits (48.636087) is larger than the coefficient on sales, but is this difference statistically significant? The test statistic is
\[ t=\frac{\left(\hat{\beta}_{profit}-\hat{\beta}_{sales}\right)-0}{se\left(\hat{\beta}_{profit}-\hat{\beta}_{sales}\right)} \]
In R, this test can be implemented using the glht() function from the multcomp package:
## [1] "(Intercept)" "sales" "mktval" "profits" "ceoten"##
## Simultaneous Tests for General Linear Hypotheses
##
## Fit: lm(formula = salary ~ sales + mktval + profits + ceoten, data = mydata)
##
## Linear Hypotheses:
## Estimate Std. Error t value Pr(>|t|)
## profits - sales == 0 30.4 278.0 0.109 0.913
## (Adjusted p values reported -- single-step method)##
## Simultaneous Confidence Intervals
##
## Fit: lm(formula = salary ~ sales + mktval + profits + ceoten, data = mydata)
##
## Quantile = 1.9739
## 95% family-wise confidence level
##
##
## Linear Hypotheses:
## Estimate lwr upr
## profits - sales == 0 30.4026 -518.2618 579.0671What about ceoten compared to sales?
##
## Simultaneous Tests for General Linear Hypotheses
##
## Fit: lm(formula = salary ~ sales + mktval + profits + ceoten, data = mydata)
##
## Linear Hypotheses:
## Estimate Std. Error t value Pr(>|t|)
## ceoten - sales == 0 12713 5635 2.256 0.0253 *
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
## (Adjusted p values reported -- single-step method)##
## Simultaneous Confidence Intervals
##
## Fit: lm(formula = salary ~ sales + mktval + profits + ceoten, data = mydata)
##
## Quantile = 1.9739
## 95% family-wise confidence level
##
##
## Linear Hypotheses:
## Estimate lwr upr
## ceoten - sales == 0 12712.6292 1590.0204 23835.23801.4 Log transformations
This data provides a good example of why visualizing the data can be helpful. By looking at histograms and scatter plots, you can see the effects of log transformations. .
1.4.1 Histograms
Try making histograms of salary and log(salary)
Try making histograms of sales and log(sales)
First, here is a histogram of sales.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.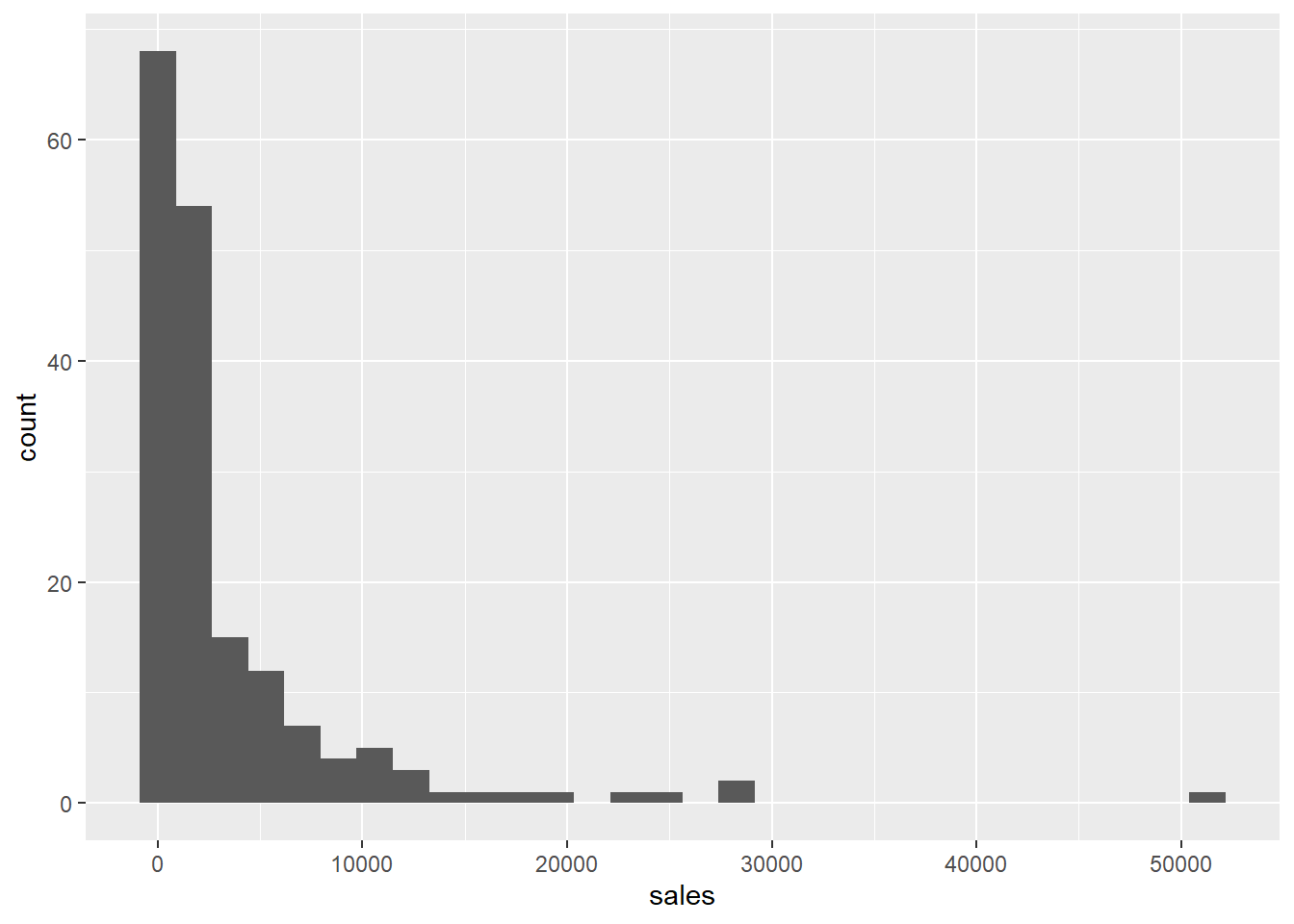
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.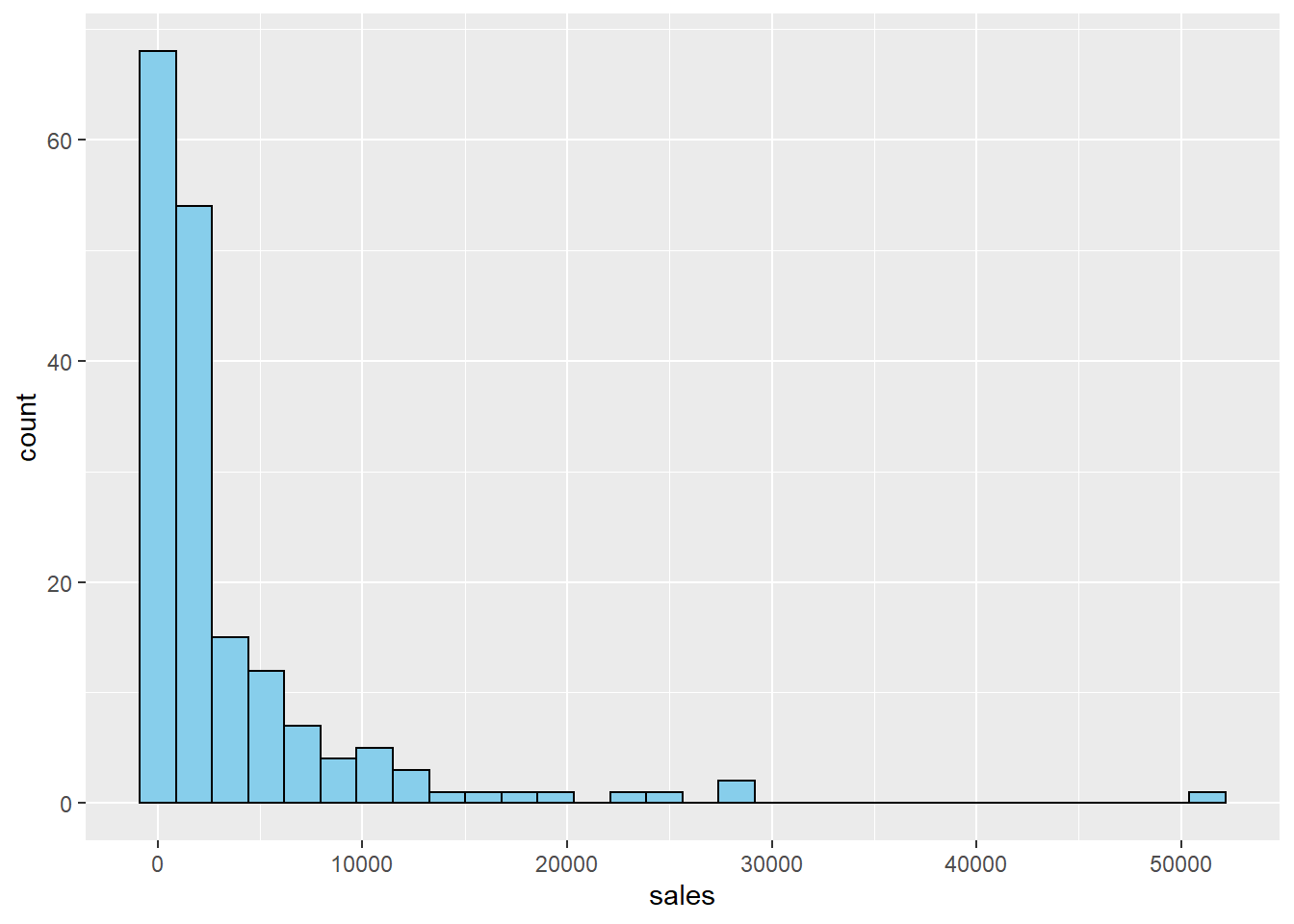
This distribution is very skewed. Here is the histogram of \(log(sales)\)
mydata$logsales <- log(mydata$sales)
ggplot(mydata,aes(x=logsales)) + geom_histogram(fill="skyblue", color="black")## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.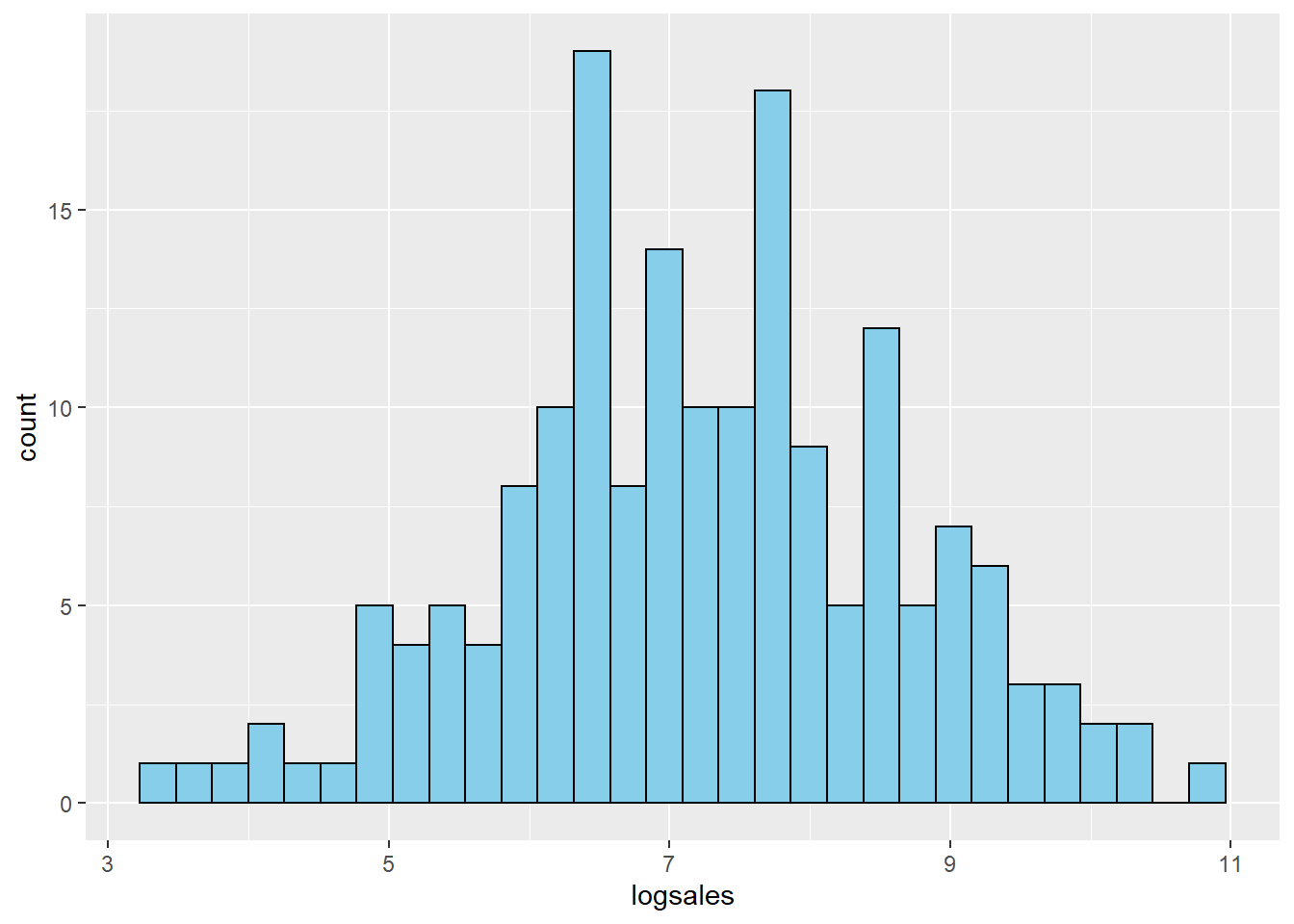
We notice a similar pattern with salary.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
mydata$logsalary <- log(mydata$salary)
ggplot(mydata,aes(x=logsales)) + geom_histogram(fill="skyblue", color="black")## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.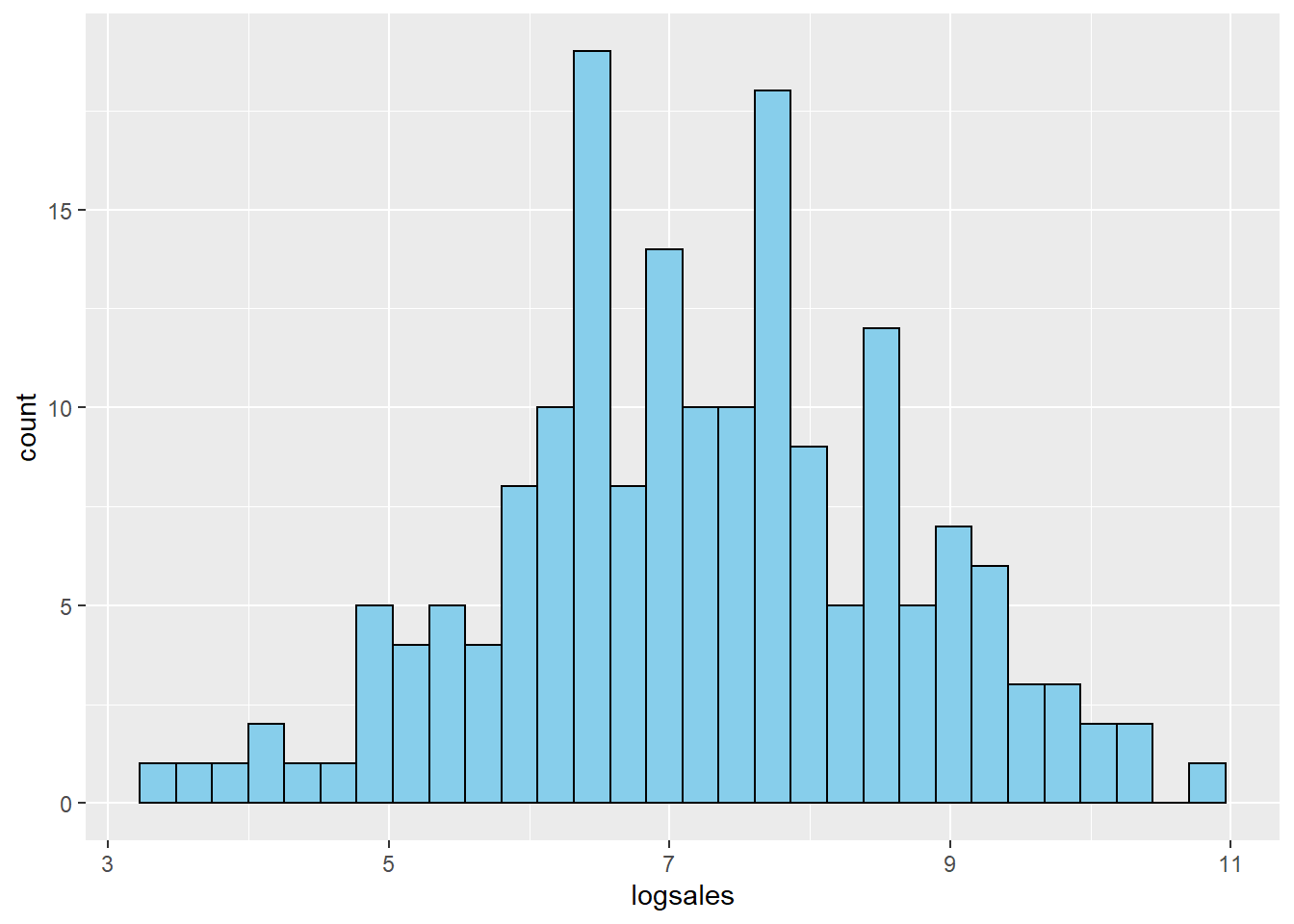
1.4.2 Scatter plots
You can also see how log transformations spreads out the data by looking at scatter plots of salary or log(salary) (y) versus sales or log(sales) corresponding with the four different models. I colored the points based on age just as an example. That has nothing to do with the log transformations.
##plot(mydata$salary,mydata$sales)
ggplot(mydata,aes(y=salary,x=sales,col=age))+geom_point()+ scale_colour_gradientn(colours=rainbow(3)) + geom_smooth(method='lm',se=FALSE,col='black')## `geom_smooth()` using formula 'y ~ x'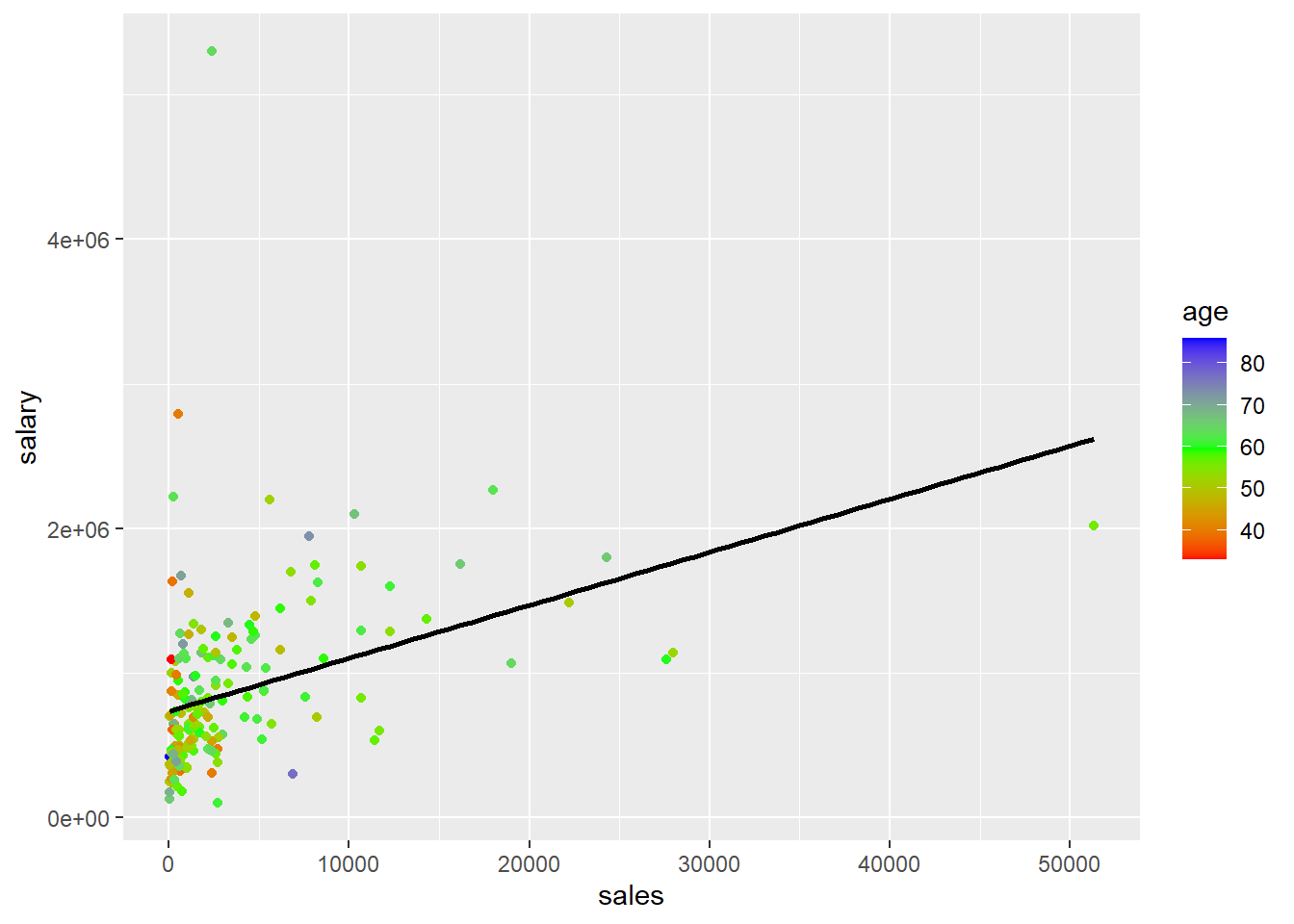
##plot(mydata$salary,mydata$sales)
ggplot(mydata,aes(y=salary,x=logsales,col=age))+geom_point()+ scale_colour_gradientn(colours=rainbow(3)) + geom_smooth(method='lm',se=FALSE,col='black')## `geom_smooth()` using formula 'y ~ x'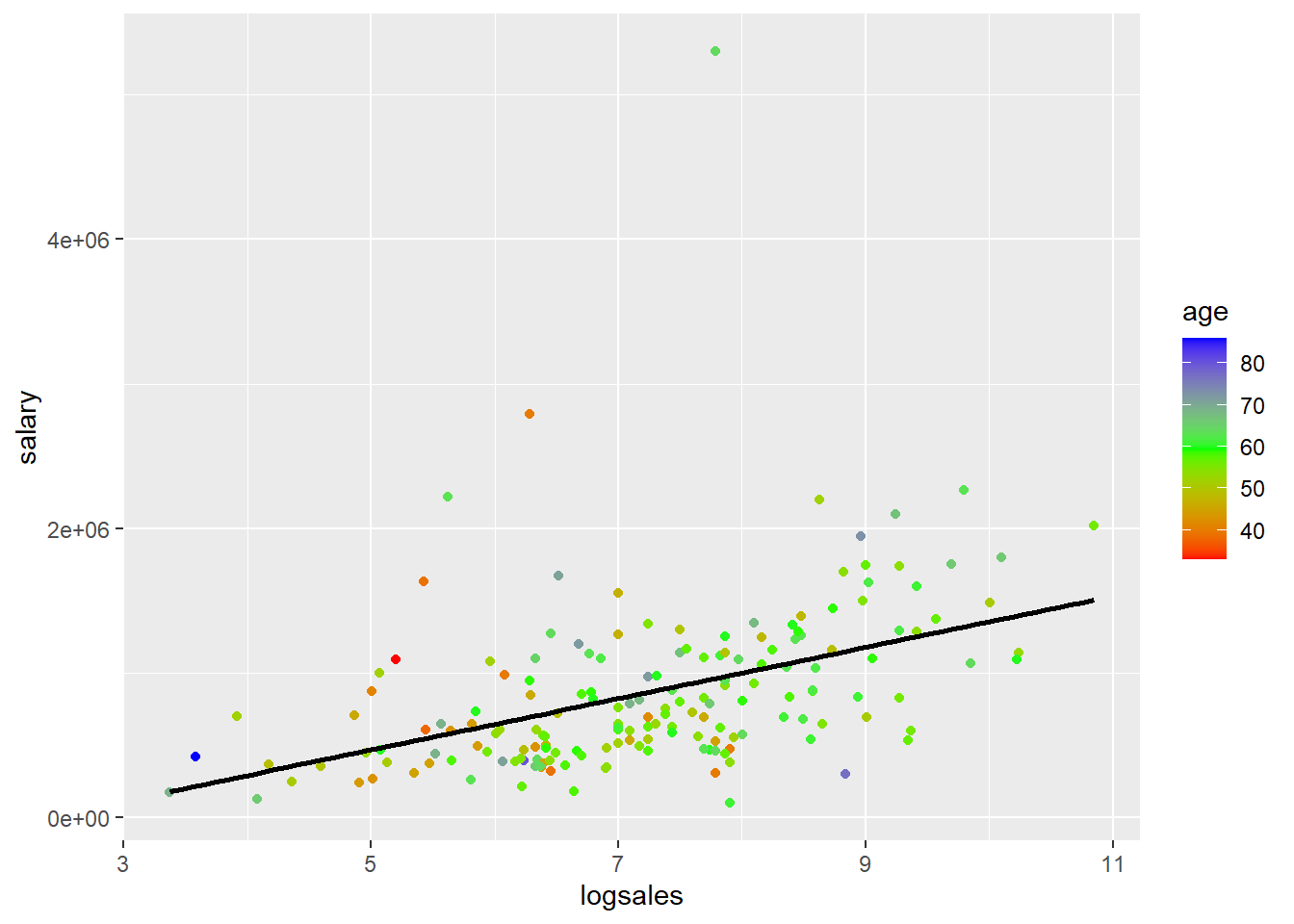
##plot(mydata$salary,mydata$sales)
ggplot(mydata,aes(y=logsalary,x=sales,col=age))+geom_point()+ scale_colour_gradientn(colours=rainbow(3))+ geom_smooth(method='lm',se=FALSE,col='black')## `geom_smooth()` using formula 'y ~ x'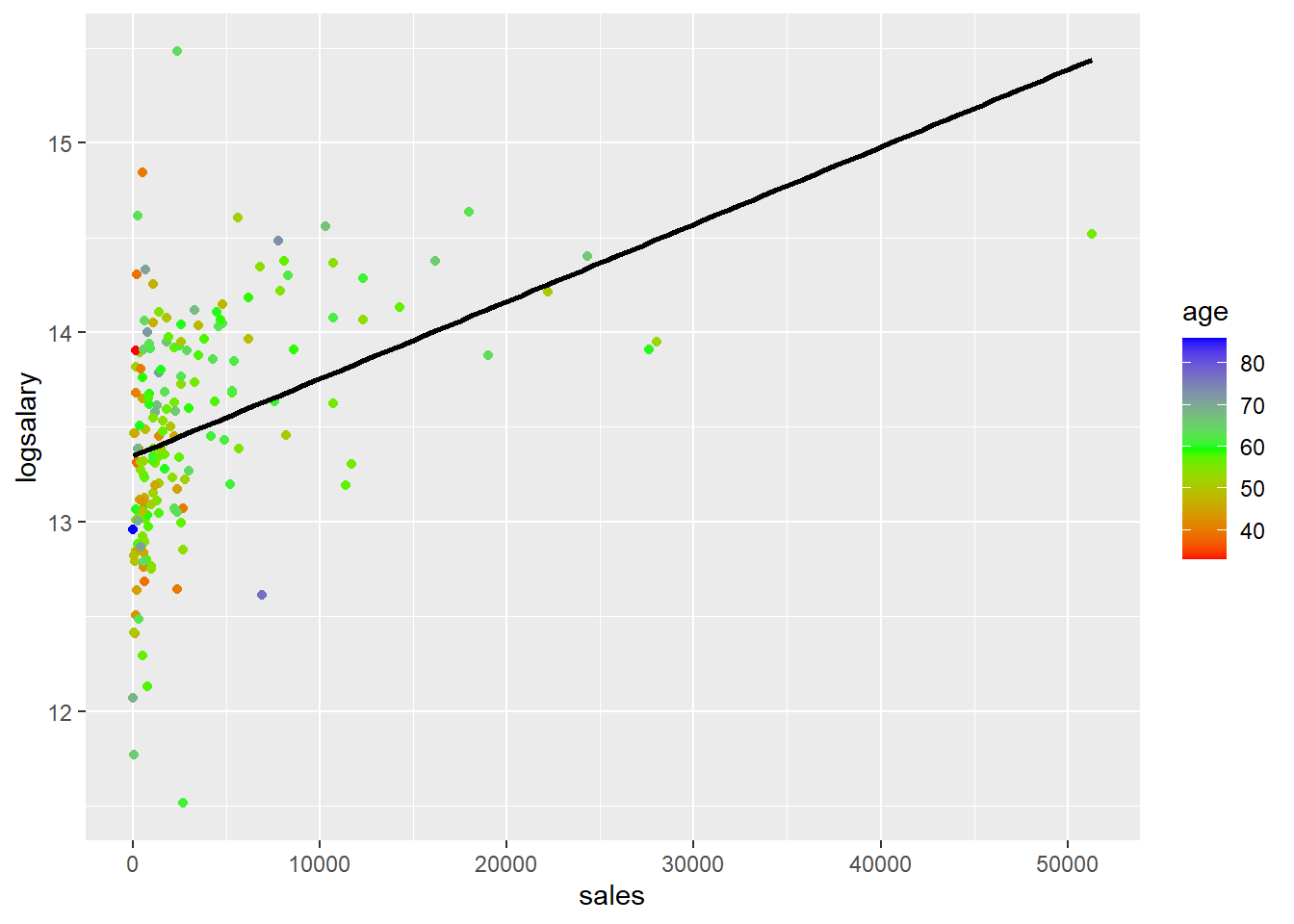
##plot(mydata$salary,mydata$sales)
ggplot(mydata,aes(y=logsalary,x=logsales,col=age))+geom_point()+ scale_colour_gradientn(colours=rainbow(3)) + geom_smooth(method='lm',se=FALSE,col='black')## `geom_smooth()` using formula 'y ~ x'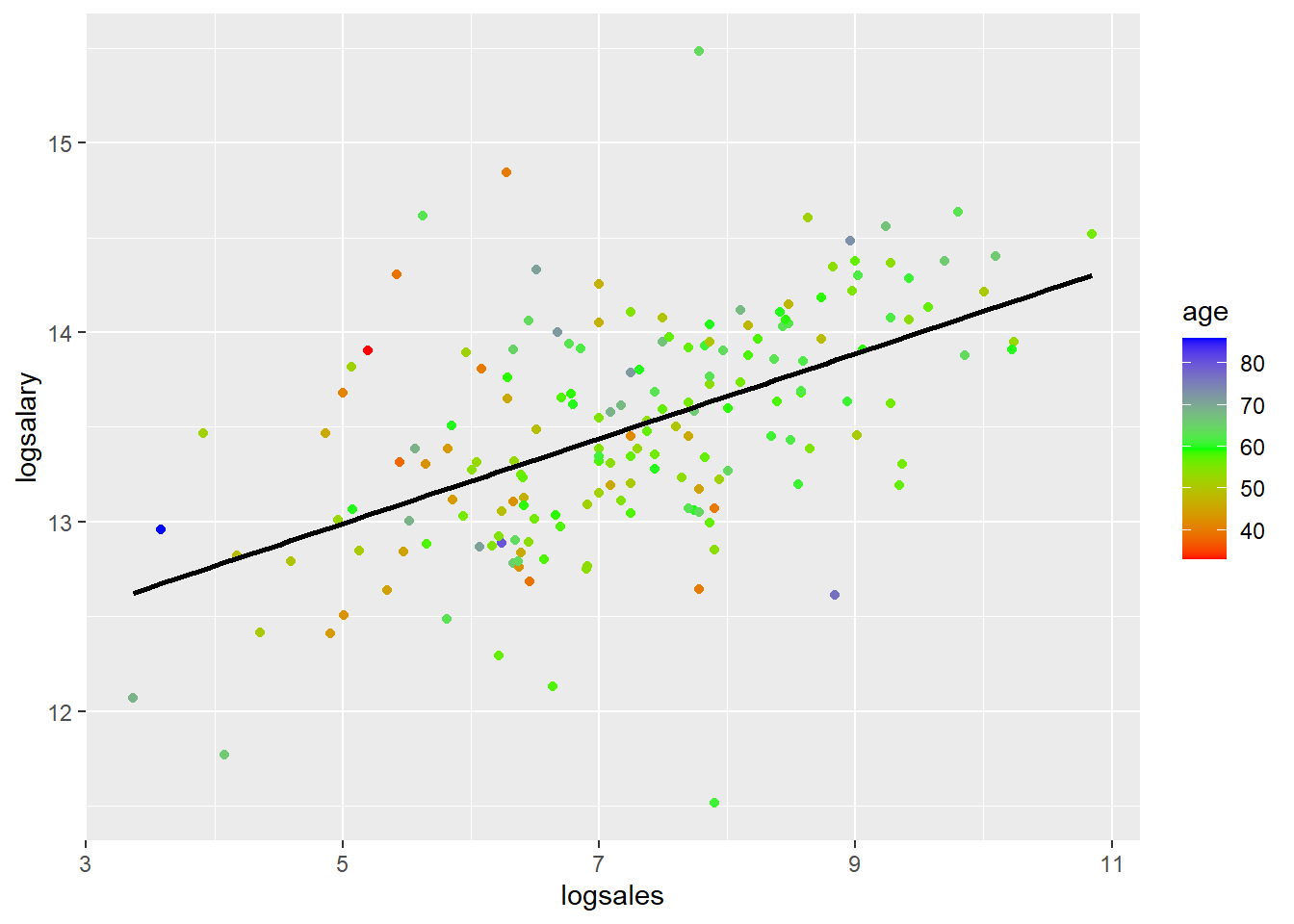
mydata$logsalary <- log(mydata$salary)
model4 <- lm(salary~sales+mktval+profits+ceoten+age,data=mydata)
model4loglevel <- lm(logsalary~sales+mktval+profits+ceoten+age,data=mydata)
model4levellog <- lm(salary~logsales+mktval+profits+ceoten+age,data=mydata)
model4loglog <- lm(logsalary~logsales+mktval+profits+ceoten+age,data=mydata)| Dependent variable: | ||||
| salary | logsalary | salary | logsalary | |
| (1) | (2) | (3) | (4) | |
| sales | 18.061 | 0.00003** | ||
| p = 0.106 | p = 0.022 | |||
| logsales | 126,644.400*** | 0.200*** | ||
| p = 0.0004 | p = 0.00000 | |||
| mktval | 21.231 | 0.00002 | 19.547 | 0.00001 |
| p = 0.183 | p = 0.280 | p = 0.205 | p = 0.330 | |
| profits | 47.528 | 0.00002 | 23.633 | -0.00003 |
| p = 0.863 | p = 0.932 | p = 0.925 | p = 0.894 | |
| ceoten | 12,390.430** | 0.011* | 13,284.340** | 0.013** |
| p = 0.042 | p = 0.066 | p = 0.025 | p = 0.025 | |
| age | 823.966 | -0.001 | -1,679.167 | -0.005 |
| p = 0.873 | p = 0.880 | p = 0.740 | p = 0.332 | |
| Constant | 570,743.300** | 13.282*** | -136,111.300 | 12.171*** |
| p = 0.042 | p = 0.000 | p = 0.680 | p = 0.000 | |
| Observations | 177 | 177 | 177 | 177 |
| R2 | 0.202 | 0.206 | 0.247 | 0.316 |
| Adjusted R2 | 0.178 | 0.182 | 0.225 | 0.296 |
| Residual Std. Error (df = 171) | 532,670.100 | 0.548 | 517,256.700 | 0.509 |
| F Statistic (df = 5; 171) | 8.633*** | 8.853*** | 11.223*** | 15.789*** |
| Note: | p<0.1; p<0.05; p<0.01 | |||
mydata$logsalary = log(mydata$salary)
model0 <- lm(salary~sales,data=mydata)
model0loglevel <- lm(logsalary~sales,data=mydata)
model0levellog <- lm(salary~logsales,data=mydata)
model0loglog <- lm(logsalary~logsales,data=mydata)| Dependent variable: | ||||
| salary | logsalary | salary | logsalary | |
| (1) | (2) | (3) | (4) | |
| sales | 36.694*** | 0.00004*** | ||
| p = 0.00000 | p = 0.000 | |||
| logsales | 177,149.100*** | 0.224*** | ||
| p = 0.000 | p = 0.000 | |||
| Constant | 736,355.200*** | 13.347*** | -415,105.000** | 11.869*** |
| p = 0.000 | p = 0.000 | p = 0.046 | p = 0.000 | |
| Observations | 177 | 177 | 177 | 177 |
| R2 | 0.145 | 0.168 | 0.186 | 0.281 |
| Adjusted R2 | 0.140 | 0.163 | 0.182 | 0.277 |
| Residual Std. Error (df = 175) | 545,008.600 | 0.554 | 531,513.300 | 0.515 |
| F Statistic (df = 1; 175) | 29.576*** | 35.327*** | 40.096*** | 68.345*** |
| Note: | p<0.1; p<0.05; p<0.01 | |||